Ditching the Mutex
TL;DR - I wrote a multiple-producer multiple-consumer queue without any mutexes, it’s pretty fast, GitHub.
About a year ago, a colleague was explaining why Erlang is so scalable, and it essentially comes down to a lack of shared memory. When you have two or more threads which share a section of memory, then whenever a thread is writing to that memory, no other threads can perform a read or write at the same time. This can result in code spending too much time waiting for the shared memory to be available for reading/writing, and therefore poor performance.
Communication between threads in Erlang is instead achieved using a message queue. Each process has it’s own queue, and other processes can add messages to it. This sounded to me like a great model for concurrency - each thread only writes its own data, and any inter-thread communication is strictly done through a message queue. I wondered if I could create a similar system in C++. My colleague told me someone already did, and it’s called Erlang, but at present I’m enjoying C/C++ a little too much to use anything else.
I figured that mainly what this needed was a high performance concurrent message queue. In theory it would be the only point of thread synchronisation, and therefore any concurrency-related bottlenecks would happen there. I knew shared memory was slow because it involved waiting for a mutex to lock, so what about lock-free concurrent data structures I’d heard vaguely about?
For a data structure to be lock-free, it needs to allow multiple operations to happen at once (e.g. one thread adding an item to a queue, while another removes an item). If one of those threads was to be suspended part-way through, it must not stop the other(s) from finishing what they’re doing.
With only a single producer and a single consumer, this is a lot more straight-forward. This is the general idea:
|
|
The above code isn’t actually safe to run. The compiler could theoretically re-order the instructions in produce such that ready is written before data. Similarly it could re-order the reads in try_consume. Not only that, certain hardware can re-order the writes to memory, or the reads from memory. Although data was written before ready, the new value of ready could reach main RAM (and/or caches of other cores) before the new value of data.
This could cause a data-race - when more than one thread accesses a memory location concurrently, and at least one of those operations is a write. The C++ standard says this results in “undefined behaviour” - which doesn’t mean your head catches fire, or even a crash, it just means the standard can’t tell you what will happen. In reality it will probably be a torn read or torn write.
For example, if two threads are writing to the same integer, one with 42, and the other with 196704, then the lower two bytes of the former could be combined with the higher two bytes of the latter, ending up with a value of 196650. Although a simple read/write of an integer is usually atomic (meaning it can’t be observed part-done), it’s not necessarily the case - for example, on x86 hardware it is only atomic if the value is naturally aligned. Simply aligning our variables may be enough to avoid a torn read/write in this case, but it still doesn’t fix the issue of reordering of reads/writes. As of C++11 though, the tools needed to fix this are in the C++ standard library, and will be portable.
The <atomic> header contains everything we’ll need, in particular the std::atomic<> type. It has a set of functions for manipulating it atomically. Generally speaking atomic versions of integral types are lock free, but this can be checked with std::atomic<>::is_lock_free. Changing ready to be a std::atomic<bool> will take care of the alignment issues for us, prevent the compiler reordering reads/writes of ready and data, and prevent the hardware from reordering memory accesses. However, we can do better.
When we write code such as if( ready ) and ready = true, we’re actually using std::atomic<>::load and std::atomic<>::store:
|
|
They have an optional parameter with which we can actually specify the memory order constraints we want for those operations.
- memory_order_relaxed - no synchronisation or ordering constraints, only atomicity is required
- memory_order_acquire - memory operations after this load cannot be reordered before it
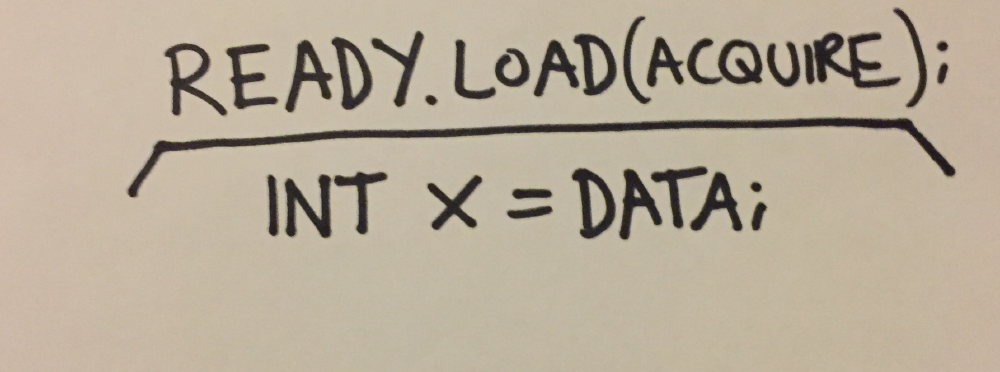
- memory_order_release - memory operations before this write cannot be reordered past it

- memory_order_seq_cst - both an acquire and release operation, plus a single total order exists in which all threads observe all modifications in the same order (I don’t use this, so won’t talk about it further, but more info here), this is the default memory order for
loadandstore
When an acquire operation in thread B reads the value which was stored by a release operation in thread A, then any side effects (that is, modifications made to other variables) before the store in A, become visible in B after the load. For example, thread A populates an array with data, then sets an atomic boolean to true with a release store. Thread B then loads the value of true with an acquire load, the data written by thread A to the array will now be visible to thread B.

So, now to rework the previous example with explicit memory ordering constraints:
|
|
The write to data can’t be reordered past the store because it uses memory_order_release, and the read from data can’t be reordered before the load because it uses memory_order_acquire. The same effect can be achieved through slightly different means - a memory fence:
|
|
Acquire and release fences work in a very similar manner to acquire and release operations, as you can see, an acquire load can be replaced with a relaxed load followed by an acquire fence, and a release store can be replaced with a release fence followed by a relaxed store.
There is an important difference between loads/stores and fences. As I said before, a call to store with memory_order_release will prevent any preceding memory operations from being reordered past it. However, it will not prevent any subsequent memory operations from being reordered before it.
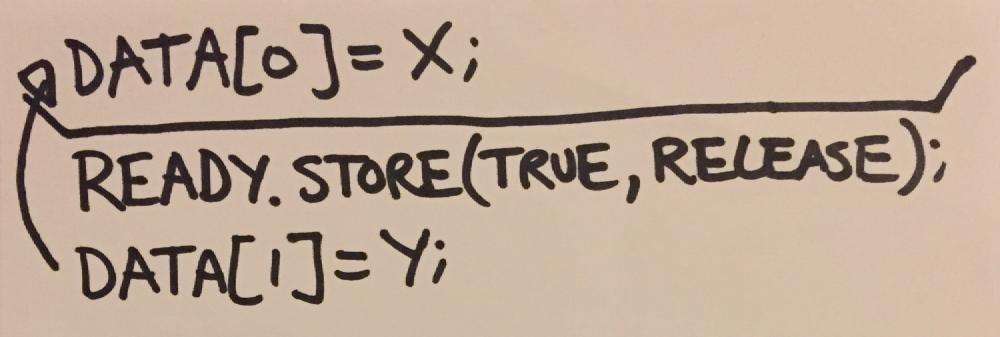
A release fence on the other hand, will stop any preceding memory operations from being ordered past any subsequent writes. Similarly an acquire fence prevents any memory operations after the fence from being reordered before any preceding reads.
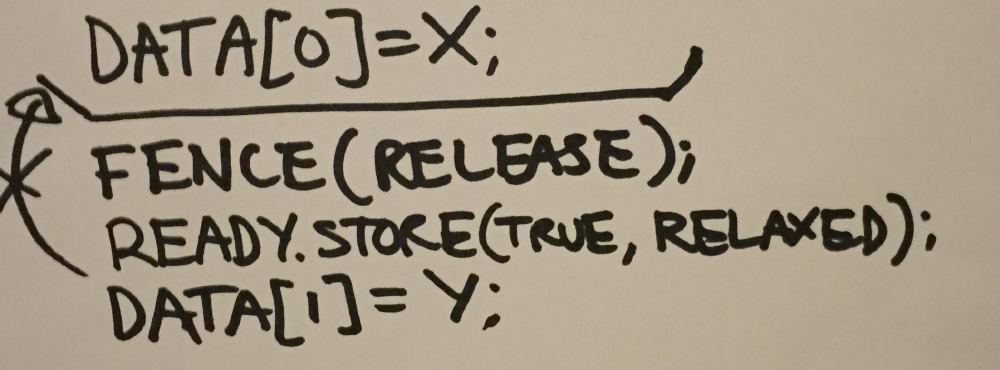
For example, if instead of using a release fence, we used a second atomic variable:
|
|
There is nothing to stop the store to ready from being reordered before the store to guard, it will only stop the assignment to data from being reordered past the store to guard.

The version with the fence on the other hand, does work, because the assignment to data cannot be reordered past any writes which come after the fence.
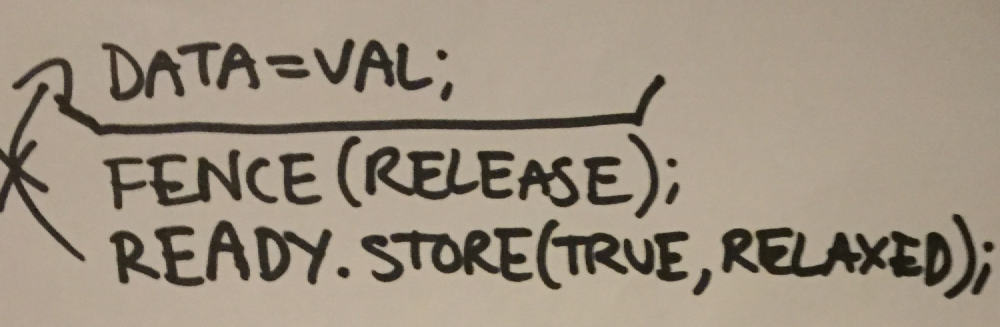
There was one memory ordering constraint which I missed earlier, because it’s easier to describe after talking about acquire/release operations - memory_order_consume. Essentially if a store is performed on an atomic object in one thread with memory_order_release, when you load the value in another thread with memory_order_consume, the side effects ordered before the store are visible after the consume, only in operations which carry a dependency from the load.
|
|
Even though the store to x cannot be reordered past the store to payload in thread 1, it’s not guaranteed to be a visible side effect in thread 2 after the load of payload. The values of foo and bar on the other hand, will be visible, because the value of payload carries a dependency into the reads of foo and bar. I won’t mention consume operations in the rest of this post though, I didn’t use them in my code, the last time I checked there aren’t any compilers which actually implement it (they just replace it with acquire). See here for more info on acquire-consume, and exactly what “carrying a dependency” means according to the standard.
So, the code now works with a single producer and a single consumer, but it gets trickier if we want multiple consumers:
|
|
This code will likely not work, as multiple threads could load a value of false for is_writing, and then go on to write to all 3 variables.
What’s needed is an atomic operation which allows us to set is_writing to true, only if it is currently false. Luckily <atomic> provides several read-modify-write (RMW) operations, and the one we can use here is compare_exchange_strong. It allows us to modify an atomic variable, only if it has an expected value:
|
|
Note the use of memory_order_relaxed for the compare_exchange_strong call - we don’t care about the memory ordering for this, as it is not used to synchronise any other variables. If we were to alter the value of ready with compare_exchange_strong (which would be pointless), then we would have to use memory_order_release to ensure the write to data was not reordered past the call to compare_exchange_strong.
I based the design of the queue itself on LMAX Disruptor, though as you’ll see if you look at the GitHub page, it’s made up of a large number of interfaces and classes, I prefer to keep things a bit simpler. What Disruptor boils down to though, is a ring buffer - a fixed-size array which behaves as if it were connected end to end. There is a head and a tail index, items are inserted at the tail and removed at the head, each time advancing the relevant index. When one of the indexes reaches the end of the array, they simply wrap around to 0 again. When the tail catches up with the head, the buffer is full. When the head catches up with the tail, the buffer is empty. It allows you to add and remove items from a queue structure without needing to allocate and free memory on the fly, or move items around.
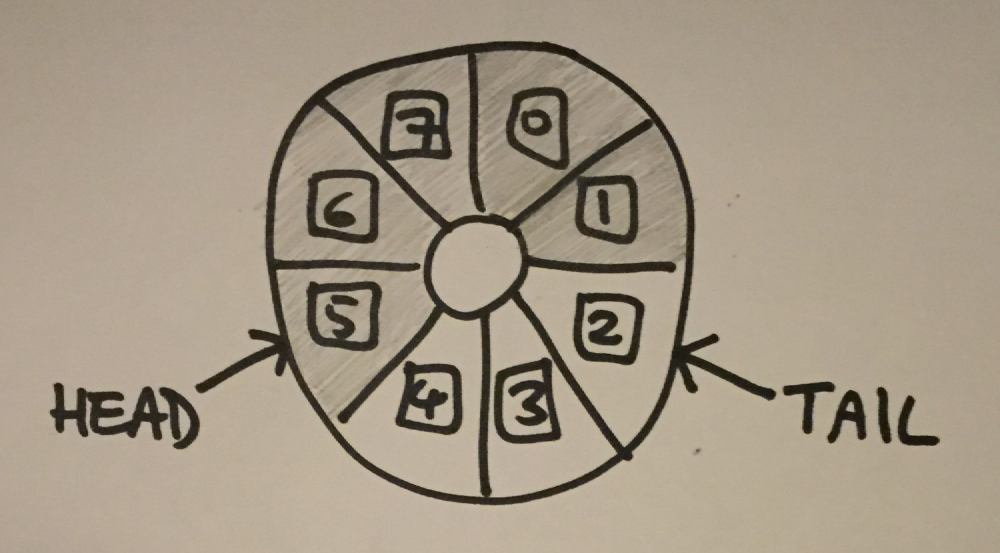
What Disruptor actually has is a pair of indexes for the head, and a pair for the tail. When a producer thread wants to insert an item in to the queue, it uses an RMW operation to read the first tail index and then advance it by 1. This allows the producer to “claim” its write index. When it has completed the write, it advances the second tail index. The same goes for reads - first a consumer thread acquires its read index, reads the value, and then advances the second read index.
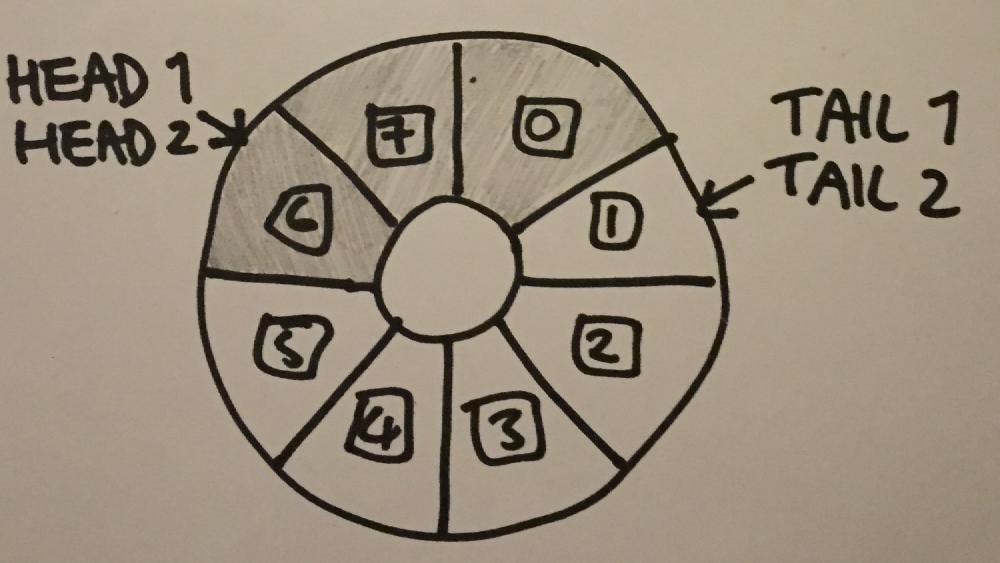
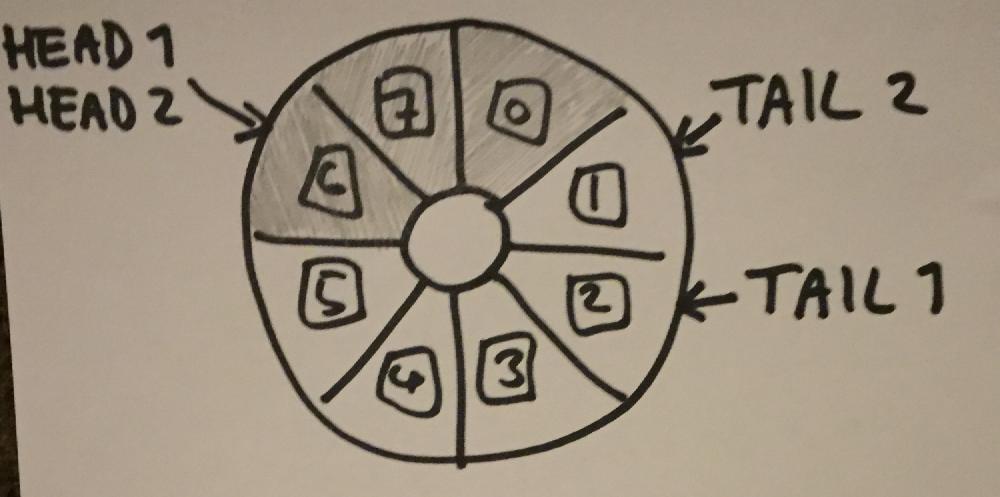
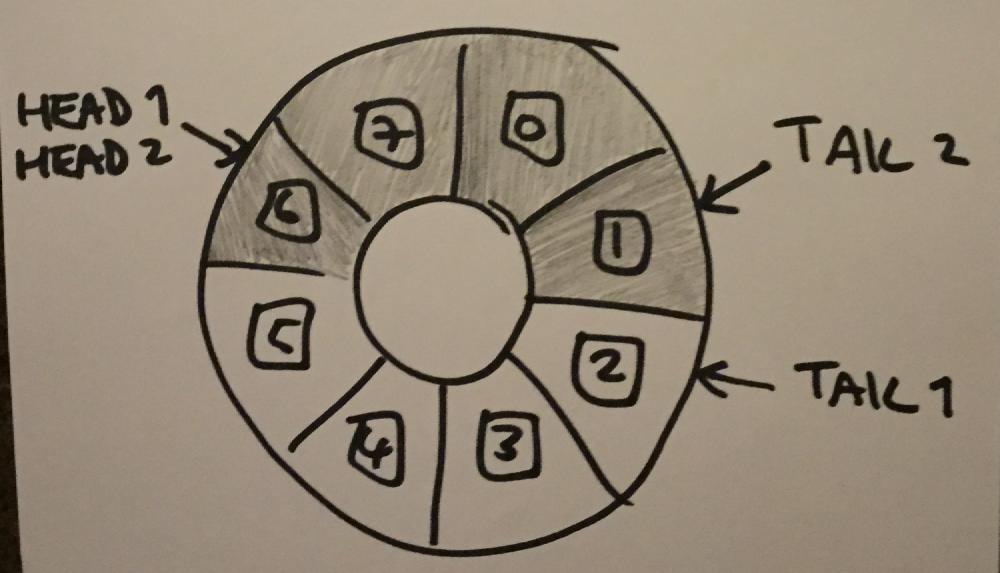
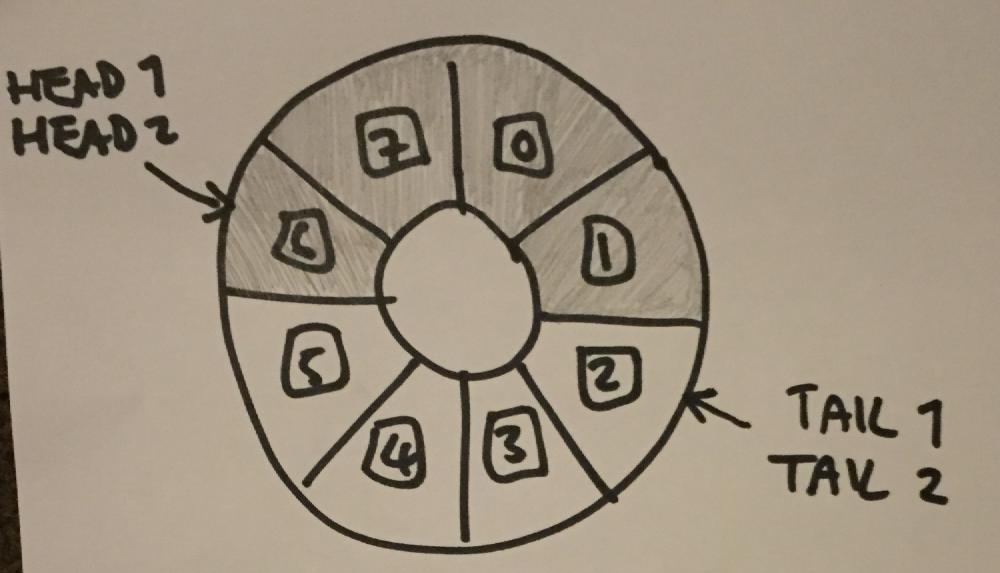
You might be thinking “but didn’t you only need multiple producers and a single consumer?” The answer is yes, but multiple consumers seemed more interesting, and I’d sort of forgotten by now what the original brief was. On to implementation - I found fences a bit easier to get my head around, and given the added memory ordering constraints which they provided, I decided to write my queue with relaxed loads and stores, and purely fences for synchronisation. Initially I thought of doing something like this:
|
|
This might seem OK at first, but there’s actually a big problem here, the ABA problem. The ABA problem is when a thread reads the value of something twice, and the value is the same both times, giving the impression that nothing has changed. When what has actually happened, is another thread (or threads) has changed that value, but changed it back to the original value by the time the second read occurs. This is present in the above code, because between reading the current tail, and calling compare_exchange_strong to update tail, other threads could’ve inserted and removed enough elements for the tail to be back where it was at the time of the first read. So the call to compare_exchange_strong operation will succeed, but the queue could be full.
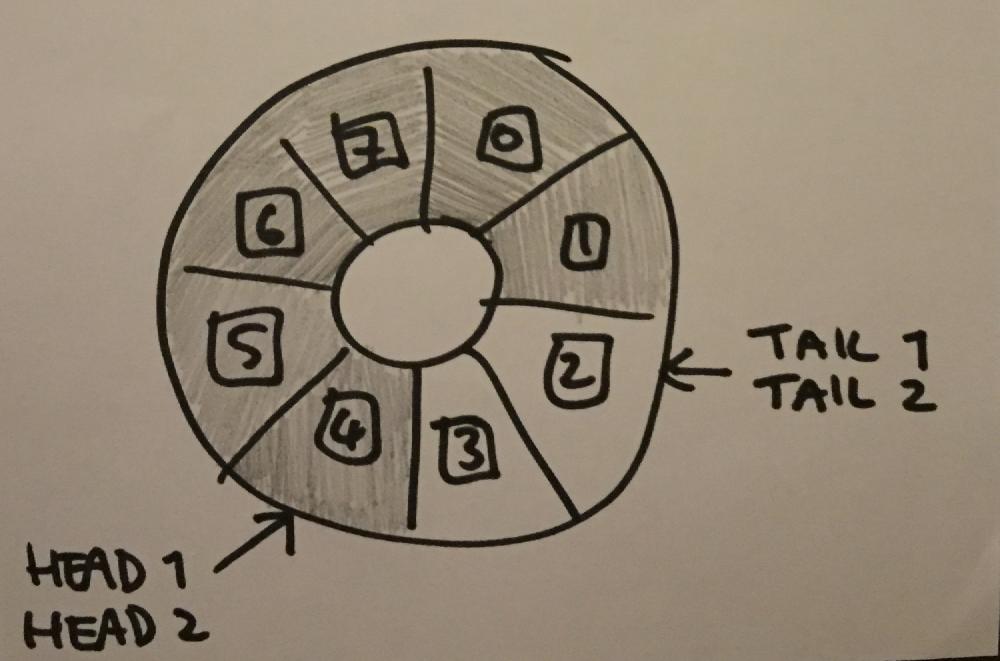
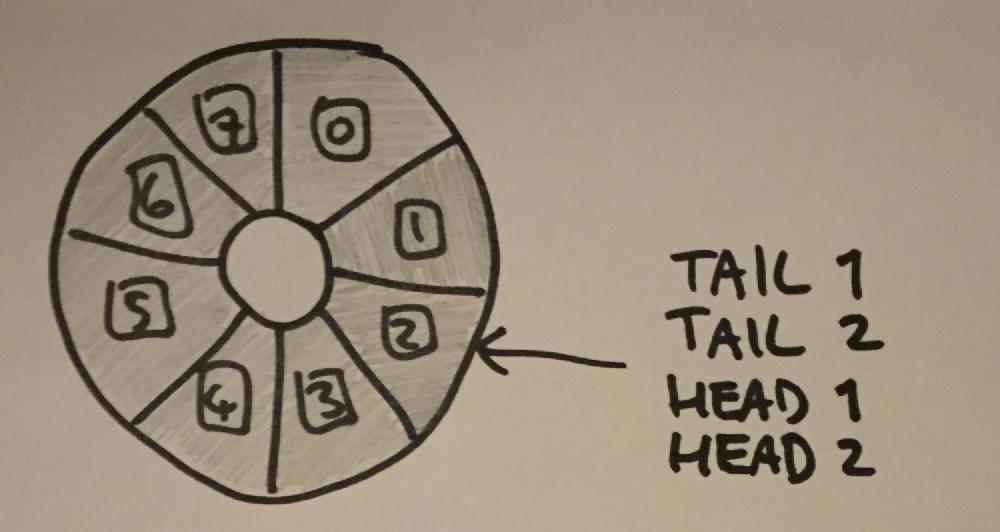
The solution I used for this was to instead have the indexes continually increase, and use the modulo of the index with the size of the ring buffer to find the actual index to use. That way if the tail has lapped the entire buffer between one read and the next, the value of tail will still be different.
|
|
The reason for testing count for greater-than or equal-to m_size, rather than just equal to m_size, is that between the read of head, and the read of tail, items could be added and removed from the queue. This could result in the observed values of head and tail being further apart than the actual size of the buffer.
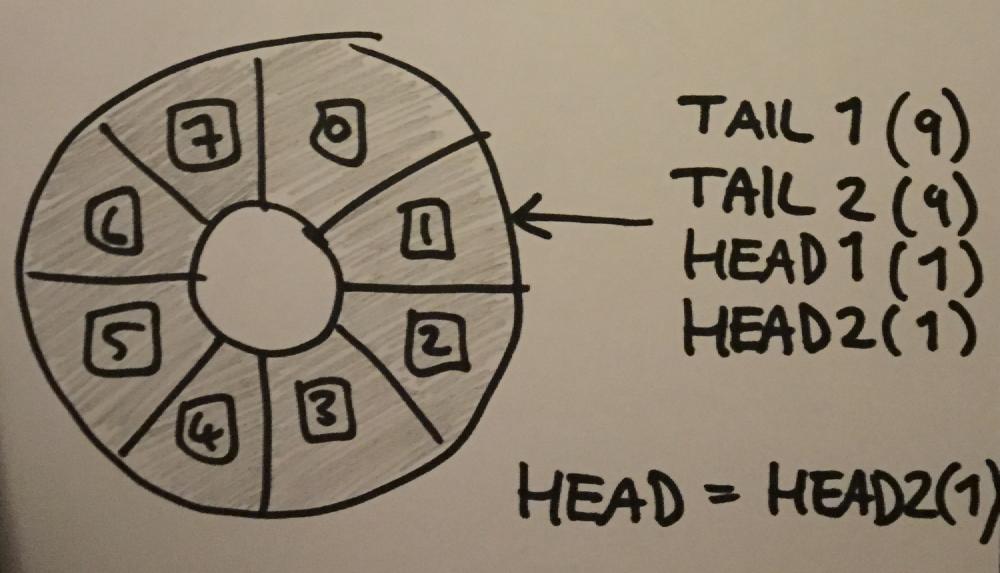
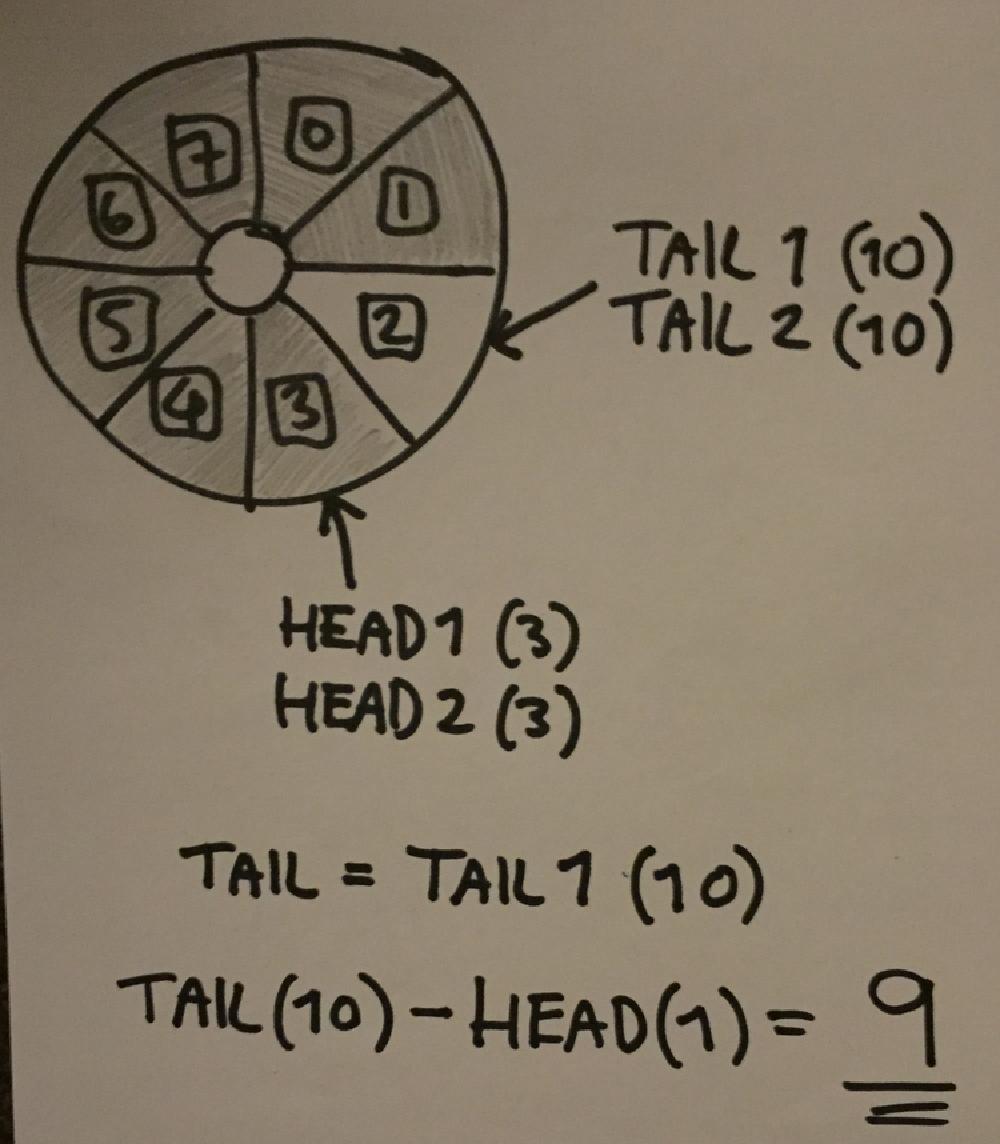
You might’ve noticed though, that eventually our head and tail indexes will overflow - and a signed integer overflow results in undefined behaviour. This will only happen after over 2 billion items have been added to the queue. It’s not likely to happen, but it’s really not impossible if a program were to make heavy use of one of these queues and run for weeks or months. We should make the indexes unsigned, as then the overflow at least doesn’t result in undefined behaviour.
Furthermore I actually wrote some code to deal with the indexes wrapping around - when 2 indexes are a distance apart which is greater than half of the maximum value of an unsigned integer, you assume that one of the indexes has wrapped. You do run the risk of the ABA problem again this way, as it is possible that between two reads of the same index, it could wrap all the way around to the same index. That really isn’t going to happen with a 32-bit index though. Another alternative could be that if you have points in your program where there aren’t multiple threads running (e.g. in-between frames in a game), you could reset the indexes to index % size.
One thing to note if you do go down this route, is that you need to make sure either the queue size is a multiple of the maximum index value, or you write code to make the indexes wrap before they actually overflow. For example, if you had a queue of size 200, and an 8-bit index (don’t ever do that, of course!), an index of 255 would write to an actual index of 55, but then it would overflow to 0 and carry on writing from an actual index of 0 rather than 56!
However, I did all of this stuff because I assumed that on x86 a 64-bit atomic integer wouldn’t be lock-free, but it actually is, so all of this has been unnecessary. With the range of a 64-bit unsigned integer, we really don’t have to worry about overflowing, so we’ll just use those from here on. I’ve used uint64_t, I like to be clear about exactly how many bits I’m using when it matters, and things like “long long” aren’t as descriptive.
So as I mentioned before, I wanted all atomic operations to be relaxed, and use fences for synchronisation. So what happens if we relax the loads of head and tail at the start of try_enqueue? If we load an old value for tail, it doesn’t matter, as compare_exchange_strong will fail if that was the case. If a stale value is loaded for head? It actually doesn’t matter either. When head is increased, it will only ever give us more space in the queue, so a stale value for head can only give the false impression of the queue being full, which we can live with.
The call to compare_exchange_strong on m_tail_1 is also fine to be relaxed, as is the load of m_tail_2. The store to m_tail_2 is going to be point at which we need a fence. That store will be used to signal to reader threads that the data is written, and can be read. We need to make sure that the compiler cannot re-order this store before the write to m_data. Also, certain weirder architectures could re-order the stores as they gradually become visible in other threads, such that the store to m_tail_2 becomes visible before the write to m_data or m_tail_1. So, a release fence just before the store to m_tail_2 will make sure that reads and writes before the fence, cannot be reordered past writes which occur after the fence. The only write to occur after the fence is the store to m_tail_2, so the writes to m_data and m_tail_1 can’t be reordered past it:
|
|
Now for try_dequeue:
|
|
When head is equal to tail then the queue is empty, and no items can be dequeued. We check for head greater-than or equal-to tail, but head can never actually be greater than tail. However, head can be greater than our observed value of tail, as between reading tail and reading head, both head and tail could be advanced by other threads adding and removing items from the queue.
So now for the fences. We’ll need a release fence like last time, for the write to m_head_2. There is another issue though, and that is the read from m_data. We can’t be sure that if even though we’re observing a certain value for m_tail_2, the corresponding side effects in m_data are also visible in this thread. As I said before, not only can writes to memory be re-ordered on certain architectures, so to can reads. This wouldn’t be a problem on an architecture like x86 where I’ll actually be running this code, but it’s also not impossible that the compiler might move the code around such that a speculative read happens before the call of compare_exchange_strong.
We need an acquire fence before the read from m_data. This ensures that all memory operations after the fence, can’t be reordered before any reads which occur before the fence. The read we’re particularly interested in is the read of m_tail_2.
|
|
I should probably mention at some point that this algorithm isn’t technically lock-free, each writer thread must wait for the previous writer to complete and advance m_tail_2 before it can also advance m_tail_2 and exit. In testing though, it still easily outperformed a mutex.
The code I had written at this point, worked with all the stress tests I threw at it, regardless of the optimisation options I compiled with - both on my x86/64 laptop, and my iPhone (this has an ARM processor, which has a weaker memory model than x86), both were fine.
Then I found Relacy, a race detector which can actually simulate loose memory models, and interleaves threaded code to test it works in all combinations. Plus it detects a load of other cool stuff, like deadlocks, livelocks, memory leaks, this is the sort of thing I would describe as “outrageously exciting” at the risk of sounding like an anorak.
When I ran my queue through Relacy, it kept detecting a data race, but it didn’t make any sense to me. It was occurring at the read from m_data, but I could see from the output that it was reading the correct value - and the read and write were not happening concurrently. The answer can be found in the C++ standard (in the version I was reading) 1.10/10:
“Certain library calls synchronize with other library calls performed by another thread. For example, an atomic store-release synchronizes with a load-acquire that takes its value from the store (29.3). [ Note: Except in the specified cases, reading a later value does not necessarily ensure visibility as described below. Such a requirement would sometimes interfere with efficient implementation. — end note ]”
In other words, if one thread writes to m_data[0], and sets m_tail_2 to 1, and another thread writes to m_data[1], and sets m_tail_2 to 2, then if a reader thread observes m_tail_2 as 2, it is only guaranteed to see the data in m_data[1], not m_data[0].
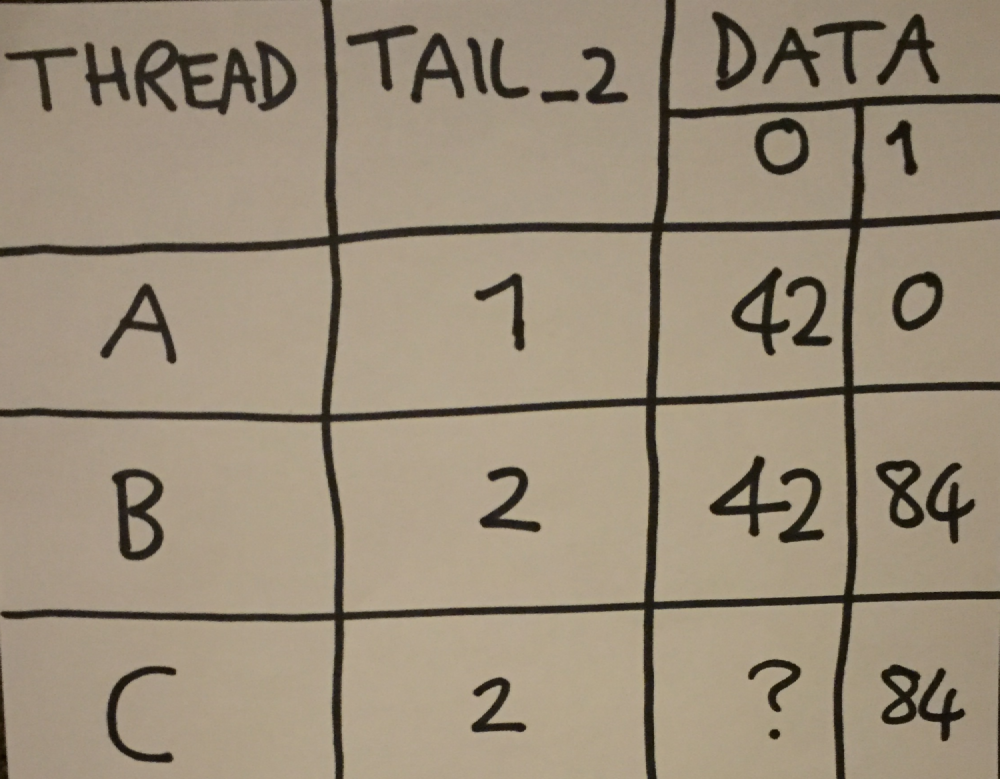
There is an exception to this though, and that is a release sequence - 1.10/9:
“A release sequence headed by a release operation A on an atomic object M is a maximal contiguous subsequence of side effects in the modification order of M, where the first operation is A, and every subsequent operation
(9.1) — is performed by the same thread that performed A, or
(9.2) — is an atomic read-modify-write operation.”
A release sequence is started by a release operation on an atomic object, and continues while operations on that atomic object are either performed in the same thread as the initial store, or are RMW operations. These RMW operations allow the side-effects of earlier writes to be visible even when loading later values, for example:
|
|
The release sequence rule means that although thread 3 may only see the value 3 for the dummy variable, it will still see the correct value in data[0]. This is because after the initial store to dummy in thread 1, all the other modifications in thread 2 are RMW operations.
Now, how much this matters, really depends on how much you care about the C++ standard. Personally, I don’t care a whole lot. Any actual application that I would write is at present going to run on x86/64 hardware, and its strong memory model is quite forgiving. I decided to “do it properly” for two reasons, firstly if I’m writing “general purpose” code and putting it up on GitHub, I feel some need to comply with the standard. Secondly, I was using relacy to test my code, and relacy will understandably treat this as an error.
So I went ahead with trying to fix it. I wondered if I could use the release sequence rule to make sure all try_enqueue side effects were visible in try_deque. I couldn’t think of a way of making all operations on m_tail_2 in try_dequeue RMW operations, so I had to go back to the drawing board.
To begin with I thought - no problem, just have each item in m_data be a struct, which has a bool, switch it to true after writing is complete, readers wait for it to be true, read the value, then switch back to false.
|
|
Simple, but still doesn’t work. In the code for dequeue, if we load the ready part of the item and find the value to be true (i.e. ready to be read), we don’t have a way of knowing whether we’re reading the most recent value of true, or the value from a previous store.

What’s needed is an integer which is increased with every write. An obvious value to use for this, is the current tail value:
|
|
If we’re now using version to signal when the item is ready, then there’s actually no point in the dual indexes. Previously, we’d use m_tail_1 to acquire our write index, and then use m_tail_2 to signal to a reader thread that the item is ready. Now we can just have a single head and a single tail, use an RMW operation to claim our index, and use version to signal when reading/writing is complete.
So if both try_enqueue and try_dequeue are going to be increasing version, what makes most sense is for try_enqueue to wait for version to equal tail. When it does, it writes its data, and then increments version. Try_dequeue on the other hand, will wait for version to equal (head + 1), as this will be the value set by try_enqueue when writing was finished. When it is done reading the data, it sets version to (head + capacity), this will be the value of tail when dequeue operations wrap back around to this same index in the buffer.
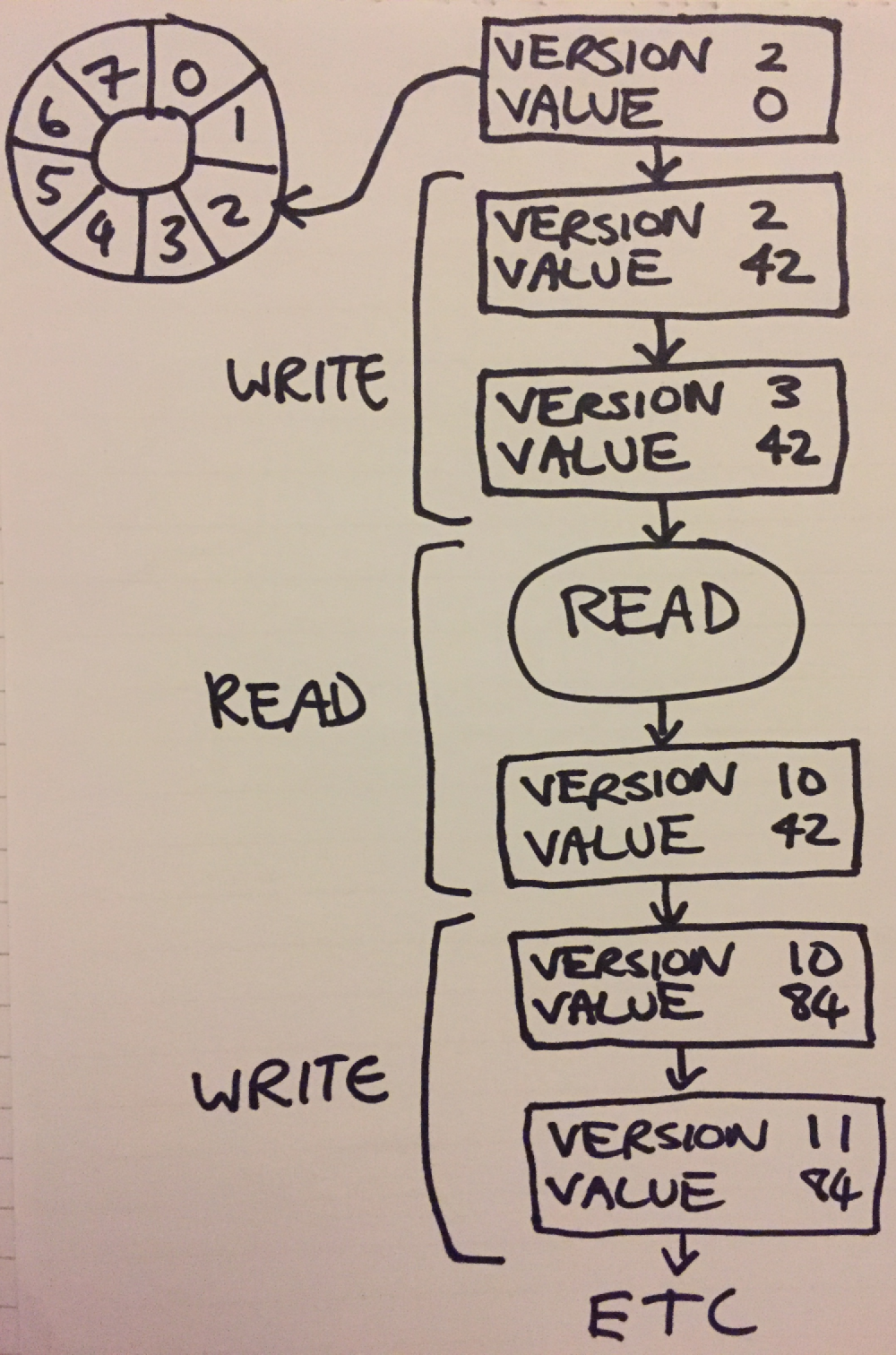
|
|
This code is actually a fair bit simpler than with dual indexes, it also has the added bonus that readers/writers of index (n + 1) do not need to wait for the reader/writer at n to finish (whereas before, writers would have to wait in try_enqueue for m_tail_2 to catch up before they’d be able to increment it themselves). It still isn’t lock free exactly, as a thread suspended in try_enqueue would eventually result in the queue being unusable when head caught up to tail.
A very important final step is to have a think about false sharing. If two pieces of data are being written on different cores, it will seriously affect performance if they share a cache line. This is because each core (at least on the hardware in my machine) has its own L1 and L2 cache, and when one core writes to that cache line, the memory system will need to update the L1 and L2 caches in the other core. Keeping the caches in sync like this, comes at a cost to performance. The indexes in the queue will suffer from false sharing, as will the actual items. Let’s have a go at fixing that next:
|
|
The alignas specifier is a C++11 feature, and is a standardised version of __declspec( align( x ) ). The using statement in AlignedAtomicU64 allows the type to inherit all the constructors from std::atomic<uint64_t>. When allocating the array of items, due to the alignment requirements, it’s important not to use new or malloc. On windows, the call needed is _aligned_malloc, as well as _aligned_free in the destructor. If you want to verify that the memory layout is looking correct, the memory window in Visual Studio is your friend.
So that’s it for my not quite lock free queue - so how does it perform? Under normal circumstances, pretty well, and much faster than just using a mutex. Not always though, in situations of high contention, it actually ends up being slower. Depending on the implementation of your mutex, if a thread can’t acquire the mutex, it will be put to sleep. This allows other threads to get on with doing what they need to do.
My queue on the other hand, can get into situations where for example, the queue is full, and all the producer threads keep spinning and attempting to add items. This is valuable time that ought to be spent running consumer threads, so that the queue would be able to clear out. For this reason in my tests I had reader/writer threads yield when their operation on the queue failed. I could’ve put some code in try_enqueue and try_dequeue which would retry the operation a number of times, then sleep, or something like that. Ultimately though, I want to leave that up to the caller. If an operation fails, and the caller has other stuff they can do before trying again, then they should be able to.
At the end of the day, the main thing is - keep contention to a minimum. If threads need to send a large number of messages to each-other, consider buffering them, and sending blocks of messages at a time. In future I’d like to build a buffered queue which handles this automatically, and uses this one under the hood. Anyway, that’s a job for future Joe - congratulations if you made it this far!
Further reading: preshing.com, C++ Concurrency in Action, Atomic<> Weapons by Herb Sutter